Lets make a Commodore 64 Text Adventure Game!A simple tutorial by John Christian LonningdalC64 Basic Optimizations
Here is a short summary of optimizations you can do in basic to reduce the amount of memory
used or improve the performance of your basic code.
Everything is stored literally in your code
One thing you should always think about is that the basic code is stored almost like a raw text file
except for the line numbers "in front of" each line. Note that the line numbers in e.g. a GOTO statement
is stored literally with no optimization whatsoever including whatever whitespace you add there! GOTO 10000 would actually be stored in
7 bytes, 1 for the opcode, 1 for the space and 5 for the number even though the number could have been stored in 2 if it was binary encoded.
Which brings us to the first optimization:
GOTO10 is better than GOTO 1000
If you do a lot of GOTOs (who doesnt in basic programs) its best to do these to low line numbers,
not only is the code shorter, it is also faster. In extreme examples where performance isnt critical
you can actually create call tables in the start of the code, so instead of calling GOTO 10000 from
ten places in the code you can change it to GOTO 2 and have a GOTO 10000 on line 2. The bytes you save
naturally depends on how often you have this call. If you call it 10 places in the code you will save
a whopping 12 bytes! :) - Not much really but you should be aware of this if you have a lot of jumping
around in the code.
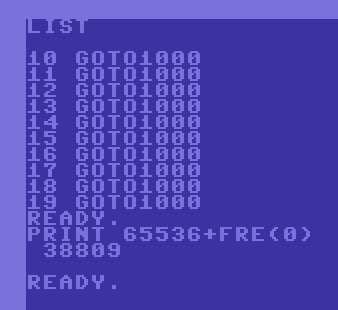 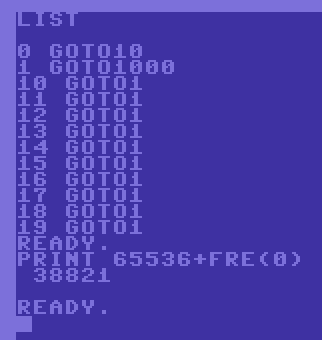
Sample code showing the difference including the necessary jump over the jump table from the start.
Actually the GOTO and GOSUB instruction is always faster to reach lower numbers than higher simply because
it has to sequencially loop through all lines from the top and match the line number to find where it
should go to. The longer your basic program gets the slower it is when it reaches the higher line numbers
if the code contains lot of gotos. Executing the next line after the previous one is not slow as well as
FOR and WHILE loops since the basic interpreter keeps track of where it should go back for the next iteration.
Arrays also eat memory
As you start working with data structures you soon learn that its much easier to just index into an array
to read out the value you need. Fortunately for literal strings the variables points into your basic code
so they only take up the space they need in the code. However, each variable takes 7 bytes of storage from
the stack in runtime. An array takes 7 bytes for the array variable and 3 bytes each index so a DIM A$(10)
will take 7+(10*3)=37 bytes of memory. Although the convenience of indexing into an array is very useful
it also eats more memory than printing directly to screen if that is your goal. But this will naturally
also slow down your code. Consider the example:
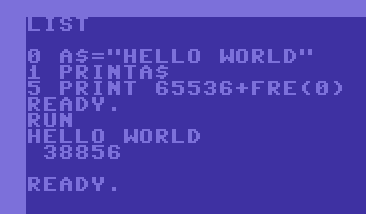 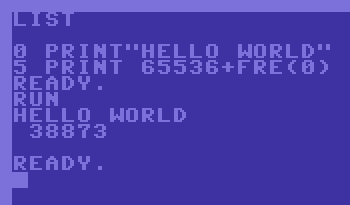
Printing a variable versus printing a string direcly (right code sample takes 17 bytes less memory in runtime).
Although the sample to the left actually contains a line more the intitialization of A$ eats 7 bytes of stack
memory and the code to initialize the variable is always in memory also. But naturally every use of this
later will only require a print opcode and the variable name. However printing directly is always more efficient
since the printing will only require a print opcode, the data (and a return statement if using a gosub). Again this code
will naturally always be slower since it needs to jump (and return).
The sample below will demonstrate this when using arrays:
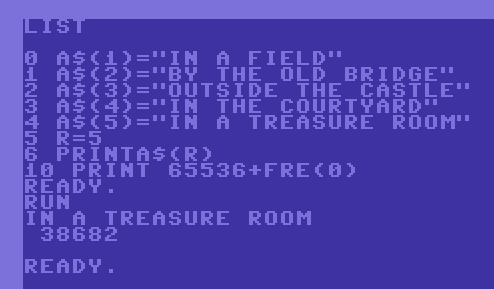
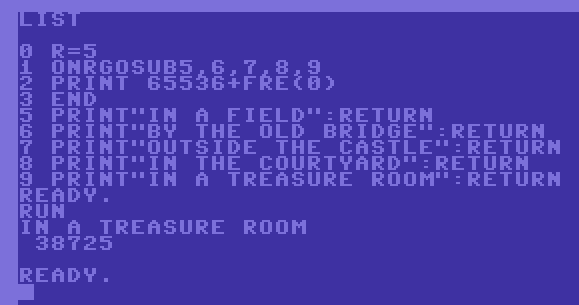
The bottom code uses 43 bytes less memory in runtime.
Similarly its often tempting to use the DATA statement for organizing your data, but you will basically
end up doing just the same. First your data is stored in the code and then when you run the program
you copy the data into variables stored elsewhere in memory. Although this isnt true for strings in
which case they will actually point to the data in the DATA statement. But its no wonder why you couldnt really
do anything big in basic. Naturally a lot of people shifted towards assembly at this point where you
immediately need to learn the concept of pointers to read the memory. In that sense, the ON..GOTO and ON..GOSUB statements
acts somewhat like pointers in our sample above.
Naturally, you cant always print out the strings immediately but its better then to reuse one string
variable and initialize that depending on the "lookup". That way you can postprocess or output the string
in any way you want much like you need when accessing it through an array. However, it is clear that it becomes
impossible to have any long lookup tables simply because basic only allows 80 characters per line of code (actually
a bit more by tricking it with opcode shortcuts) so you will have to created nested ON..GOTOs to solve that
or do a fun memory trick by modifying the basic code in runtime with a poke. :) - Another trick is to
add a small assembly routine that can print out a certain line from your basic listing and just store the
strings literally in "" so that you dont confuse the basic parser (more on these tricks later).
Use single char variables
Basic variable names cant be very long, actually only two letters where the second letter can also be a number
and in the case where you have string variables you add a dollar sign to the end of this (adding % at the end indicates
an integer variable but is rarely used). Many will curse the language for being difficult to read because of this and wish the variables could be longer. But since Basic
is an interpreted language and on the C64 the editor can only handle 80 characters (2 lines) per basic line, this limitation
has its strength. (Internally basic could handle 255 chars per line). Actually to save precious bytes you should shorten your variables to maximum one character
which leaves you with 26 number variables and 26 string variables. In most cases its more than enough. A single
char variable is faster to parse than a double char.
Remove whitespace
Similarly you can add a lot of whitespace to make the code easy to read, but once the code is finished you
should remove all whitespace to save more precious bytes and make the parser run faster. Often you might
wonder if the parser will get confused but the way the language is built up you can remove all whitespace.
IF A=5 AND B=3 THEN PRINT "HELLO":GOTO 100
becomes...
IFA=5ANDB=3THENPRINT"HELLO":GOTO100
It might look like a complete mess but since you can only fit 80 characters per line removing whitespace makes
sense to make the most of each line. Actually this leads us to the next tip...
Pack as many instructions as possible on one line
The parser will execute several instructions on one line a tiny bit faster than if you separate them on several lines.
Again, it will make your code harder to read and maintain, but once you have settled on something that works
you can quickly do this optimization. At the same time you might even free up some line numbers that can
come in handy later. Naturally it also saves memory space (overhead per line of basic code is 4 bytes, two bytes
for the memory pointer to the next basic line and two bytes for the line number).
10 A=0
20 FORX=1TO9999
30 A=A+X
40 NEXTX
50 PRINTA
becomes...
10 A=0:FORX=1TO9999:A=A+X:NEXTX:PRINTA
Timing the two code examples above and the bottom code is a whopping 2 seconds faster (79 seconds instead of 81).
Not an amazing optimization (the basic interpreter is quite fast at the actual next-line skip). But the packed
code example is actually 16 bytes smaller than than the first (4 bytes overhead per line of code and since
we have reduced 5 lines down to 1 there are 4 lines of overhead saved)
Variables take a lot of space and byte level data storage is hard to do
Naturally, since basic is an interpreted language they try to make datatypes as common as possible to avoid
complex implementations of logic. Well, every number variable takes 7 bytes of memory in runtime no matter what.
There is an integer datatype which has 16 bit precision and you create these by using % at the end of the variable
but in spite of this they still take as much memory as a floating point value (which all plain number variables are).
So while the 6502 processor is really good at working with bytes, basic really isnt. It lacks byte level efficiency
so any data structures you have that could benefit from being a byte array does not work very well. Actually the
only way to achieve a byte level storage is through manipulating a string which can contain any character (0-255).
To do this you have to concatenate strings using CHR$(x) where x is the byte value you want to store. Naturally
this is exceptionally slow!!! :(
The best way to achieve byte level storage is really by using POKE and PEEK. For your typical basic program you
can safely use the memory range 49152-53247 ($c000-cfff) which gives you 4KB to play with. But remember if you
need to access this often you should assign a variable the address since that will shorten your code (but will
also make it run slower). There are some unused lower addresses you can also use: 2, 42, 82, 251-254, 679-767, 1020-1023,
2024-2039 (area after screen memory but before sprite pointers). But for every POKE and PEEK, basic will convert
the value from and to a float for its internal representation, so only use this if you need byte storage of some
sort and feel spending 7 bytes per byte is a big waste. All in all you need to weight it up with the added code
you need to do these PEEKs and POKEs. Generally when you see that your program needs lots of these, you really
should consider looking into writing some assembly code instead.
Use variables for constant numbers!
Using variables naturally saves space in the code if you use them many times but more importantly they execute quite
a bit faster than having the interpreter parsing the number since the number is already parsed for the variable storage.
A simple code example will show you this:

The loop using the variable in the border color poke is 4 times faster!
Jump Tables!
Now I will move into more complex and possibly dangerous tricks that will boost your basic programs with new
functions you possibly didnt know about. They involve runtime modification of the actual basic code in order
to achieve shorter code. The first one out is the superpowered ON...GOTO and ON...GOSUB. The conditional jump
is a very good way of avoiding arrays of strings for example since we can instead initialise one single variable
or output direcly based on an index instead of filling variables with data and index an array. Our earlier example
showed how we can save memory using ON..GOSUB instead. Well, there is a limitation on this and that is the fact that
ON...GOSUB can only fit that many lines to jump to (around 26 low line numbers). Also, the way basic interprets this
indexed jump it has to count up until it reaches the number before jumping. So I propose a POKE hack! Look at this
code sample:
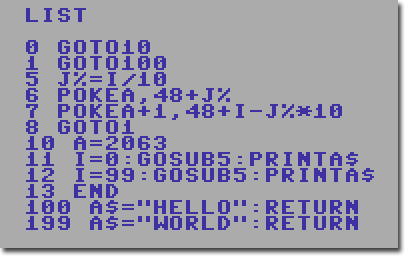
Using POKE to create a super ON...GOSUB
It might seem very complicated but what the code does is to modify the last two digits in GOTO100 on line 1
by converting the variable I to two POKEs and then jumping to this line 1 which jumps to the line that initialise
the A$ variable that will then return to the initial GOSUB. Whew, sounds a bit dangerous does it? Well you have
to be careful and not modify line 0 here since that jumps to where the code starts and will make sure that line 1
is always in the same spot in memory. This code is not very efficient since it has do to a fair amount of calculation
per indexed jump, but if it isnt time critical then its a great way to have an ON..GOSUB that can reach 100 lines.
A simple additional poke and you could reach 1000 lines with it. And it sure takes a lot less space than a long
ON..GOSUB or a whole set of lines with these to reach many.
Back to index |